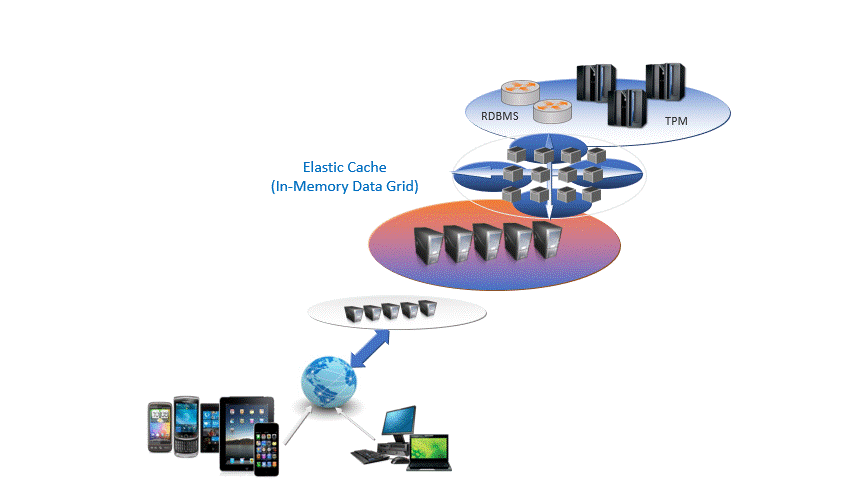
With Many Thanks to John McGarvey and Federico Senese
Yes – we have done a good job! We have decided on an odd number of Catalogs located in different LPARs and in different zones. We have studied and designed our HA-solution for the catalog servers and decided on the ultimate approach. We also have decided that our global cache solution will make use of asynchronous replicas, since our backend systems are not designed for massive requests and there are better use for our CPUs than to try to rebuild the cache organically. Yes, data might become a tad stale in the remote zone for a number of seconds, but it is OK. We can live with that.
We have decided to use the zone approach in order to make certain that an asynchronous replica will not be created in the same zone.
A zone can be associated with a datacenter at a different geography. However it is typically not a recommended practice to let a grid span datacenters. The reasons are associated with the way catalog instances interact: The problem is that sooner or later communication between the data centers will become disrupted. If one is running with quorum, the grid becomes inaccessible until communication is regained. If you are running without quorum, one would typically get a split brain condition. It is possible to recover from split brain, but the result is inherently lossy — one side wins, and the other must discard changes. A second concern is that an amount of writes will be slow, because they will require a round trip to the remote data center (as mentioned by John McGarvey).
Our Objectgrid configuration file would look something like below:
<objectgridDeployment objectgridName="Grid">
<mapSet name="mapSet" numberOfPartitions="13" minSyncReplicas="0" maxSyncReplicas="0" maxAsyncReplicas="1">
<map ref="Map1"/>
<map ref="Map2"/>
<zoneMetadata>
<shardMapping shard="P" zoneRuleRef="stripeZone"/>
<shardMapping shard="A" zoneRuleRef="stripeZone"/>
<zoneRule name="stripeZone" exclusivePlacement="true">
<zone name="zone1"/>
<zone name="zone2"/>
</zoneRule>
</zoneMetadata>
</mapSet>
</objectgridDeployment>
Assuming the shards look like below – what do we normally expect would happen should a container go down? The replicas in the other datacenter will take over the primary shards from the failing container. We would also expect the surviving container in the zone to take over the asynchronous replicas from the failing container and also create new asynchronous replicas from the new primary shards.
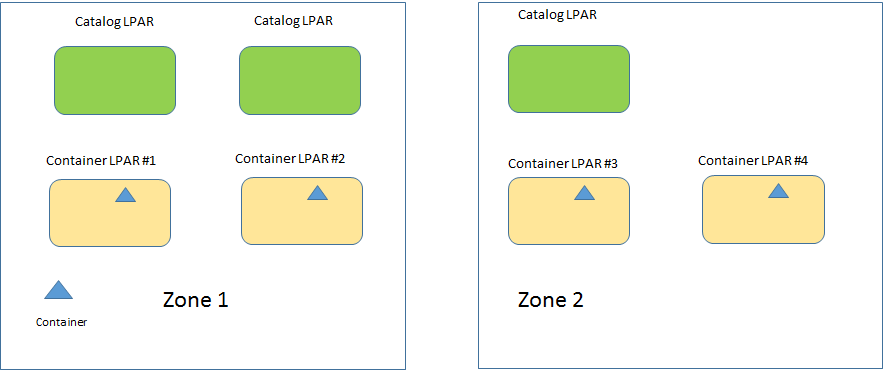
In order to visualize this, we create a scenario, where four LPARs are simulated by creating four container server processes. For the purpose of illustration, the abnormal termination of the server process CS2, residing in Zone 1, will be used to simulate the fact that LPAR #2 and/or its container process(es) have gone down, have become unresponsive or lost a network card or something similar.
Considering the above picture – where each container LPAR contains only one container. Should LPAR #2 – or the only container process in LPAR #2 (Zone 1) – go down, the LPAR(s) in Zone 2 that host the asynchronous replicas to the primary shards in LPAR #2, will start hosting the actual primary shards. Likewise LPAR #1 will take over the new asynchronous replicas from Zone 2 as well as the new asynchronous replicas from LPAR #2.
This can be further illustrated by the picture below. The top container row shows us how shards are distributed before LPAR #2 (Zone 1) goes down. The bottom container row shows us what happens by default after LPAR #2 is not available any more: LPAR #1 now manages 26 shards instead the 14, the number it originally was designed to maintain. The picture also shows us that LPAR #4 now only manages primary shards, since it took over the primary shards from LPAR #2.
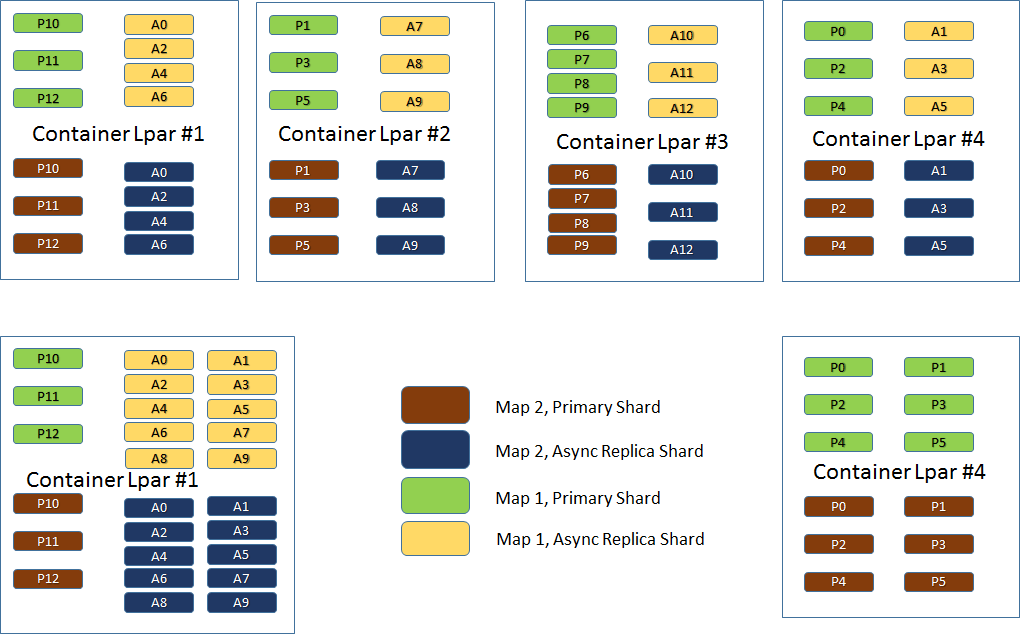
This means that the surviving LPAR in Zone 1, not only needs to host its own original shards. It actually needs to host almost twice as many shards as it needs to host during normal operations. Does it have the capacity? Most probably, since we have done the homework. Does it have to have the capacity to host twice its number of shards as it does during normal operations? No!
We are going to take a look at the server property allowableShardOverrage. This option is intended for just this situation. It is only relevant to zones and what it says is that if the capacity in a zone is less than a certain container ratio, asynchronous replica shards will not be placed in that particular zone.
If we in the example above say that: allowableShardOverrage=0.75 and LPAR #2 goes down, Websphere Extreme Scale – before handing over 12 asynchronous replica shards to LPAR #1 – will verify the number of containers available in Zone1 (only 1) after LPAR #2 (or its container) terminated in comparison with the number of containers in Zone2 (there are 2 of them). The result (0.5) is below 0.75 and thus fewer (a representative subset, or none at all) asynchronous replica shards will move over to Zone 1.
server.properties: allowableShardOverrage=0.75
startXsServer cat0 –serverprops server.properties
call startXsServer.bat cs1 -objectGridFile objectgrid.xml -deploymentPolicyFile deployment.xml -zone zone1
call startXsServer.bat cs2 -objectGridFile objectgrid.xml -deploymentPolicyFile deployment.xml -zone zone1
call startXsServer.bat cs3 -objectGridFile objectgrid.xml -deploymentPolicyFile deployment.xml -zone zone2
call startXsServer.bat cs4 -objectGridFile objectgrid.xml -deploymentPolicyFile deployment.xml -zone zone2
stopxsserver cs2 -catalogServiceEndPoints localhost:2809
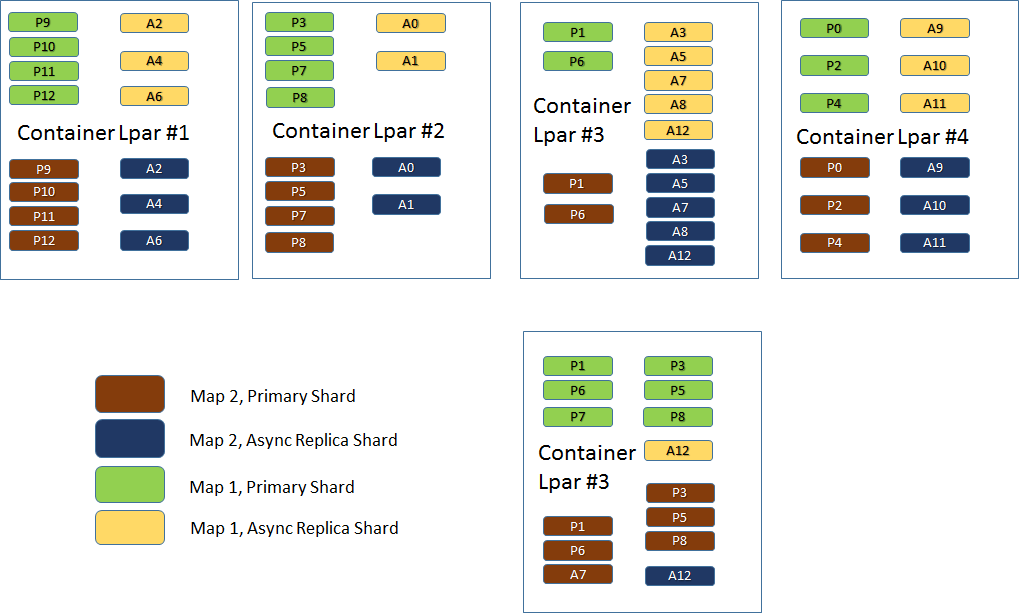
We see here that LPAR #3 (Zone 2) has taken over primary shards from LPAR #2. We also see that all asynchronous replicas managed by LPAR #2 are gone. In addition almost all asynchronous replicas managed by LPAR #3 is gone. The number of shards managed by the LPAR – and the grid – is the same as before, but in order to reach this condition a number of replicas had to be disposed of.
The result would mean that it is possible for example to bring down LPAR #2 for maintenance and feel reassured that Zone 2 will take over the primary shards and that Zone 1 will continue to work nicely, with none or little overhead. The disadvantage is of course that if the container(s), hosting the new primaries it has taken over from Zone 1, are brought down one way or another, there are no replicas available and the cache would typically need to be organically recreated, costing CPU and initial longer response times.
As always it is eventually a design decision. The negative repercussions could be dealt with from a design point of view (by for example using synchronous replicas within a zone), but on the other hand it is also possible for example see to that LPARs are large enough to deal with twice their estimated normal number of shards or simply to consider organic recreation not such a terrible disaster in relation to how often it typically would happen (probability/impact analysis). In any case allowableShardOverrage is a useful mechanism to plan and design LPAR/Software maintenance in a Websphere Extreme Scale Environment.